1R (“one rule”) is a rule learning algorithm that first appeared in 1993. It’s a baseline algorithm: if you can’t do as well as this, you need to think again. This post describes my implementation in Rust. For me, implementing an algorithm is a fun way to improve my knowledge of a language and ecosystem.
TL;DR - where’s the code?
oner_induction is the 1R learning algorithm. It takes labelled data and produces a rule. The data has to be discrete (that is categorised, not numeric). There are many algorithms for turning numeric values into categorical data (binding, quantising).
oner_quantize is an implementation, to the best as I can figure it, of the quantisation algorithm in the 1R paper. You give it a column of numbers and labels, and it’ll find intervals (ranges) in those numbers.
Those are both libraries (crates, in Rust terms). I pulled them together into an application. This application, oner, reproduces some of the original 1R experiments and findings.
All other links are at the end of this post.
What does 1R do?
Given a set of labelled data, 1R picks the one attribute (feature, column) that best predicts the label. That does not mean it’s the best predictor of the data, just that it’s a simple predictor. It’s a baseline for comparison to other algorithms.
In the history of AI, 1R turns up around the time when there were developments of sophisticated rule learners, such as C4. And yet, as the title of the 1R paper from Robert C. Holte, states: “Very Simple Classification Rules Perform Well on Most Commonly Used Dataset”.
An example 1R rule might be in the form:
IF PetalWidthInCm < 1 THEN Iris-setosa
IF PetalWidthInCm >= 1 AND < 1.7 THEN Iris-versicolor
IF PetalWidthInCm >= 1.7 THEN Iris-virginica
This example is from a dataset that contains measurements of different species of Iris:
| Sepal Length | Sepal Width | Petal Length | Petal Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 5.7 | 2.8 | 4.5 | 1.3 | Iris-versicolor |
| 6.0 | 3.0 | 4.8 | 1.8 | Iris-virginica |
| … | … | … | … | … |
…and so on for 150 examples of these three species.
The problem is to classify a species from the measurements. This 1R rule has selected the petal width as the most useful attribute. It doesn’t do too badly. I’ve tried to illustrate the rule boundaries plotted against each of the different plants:
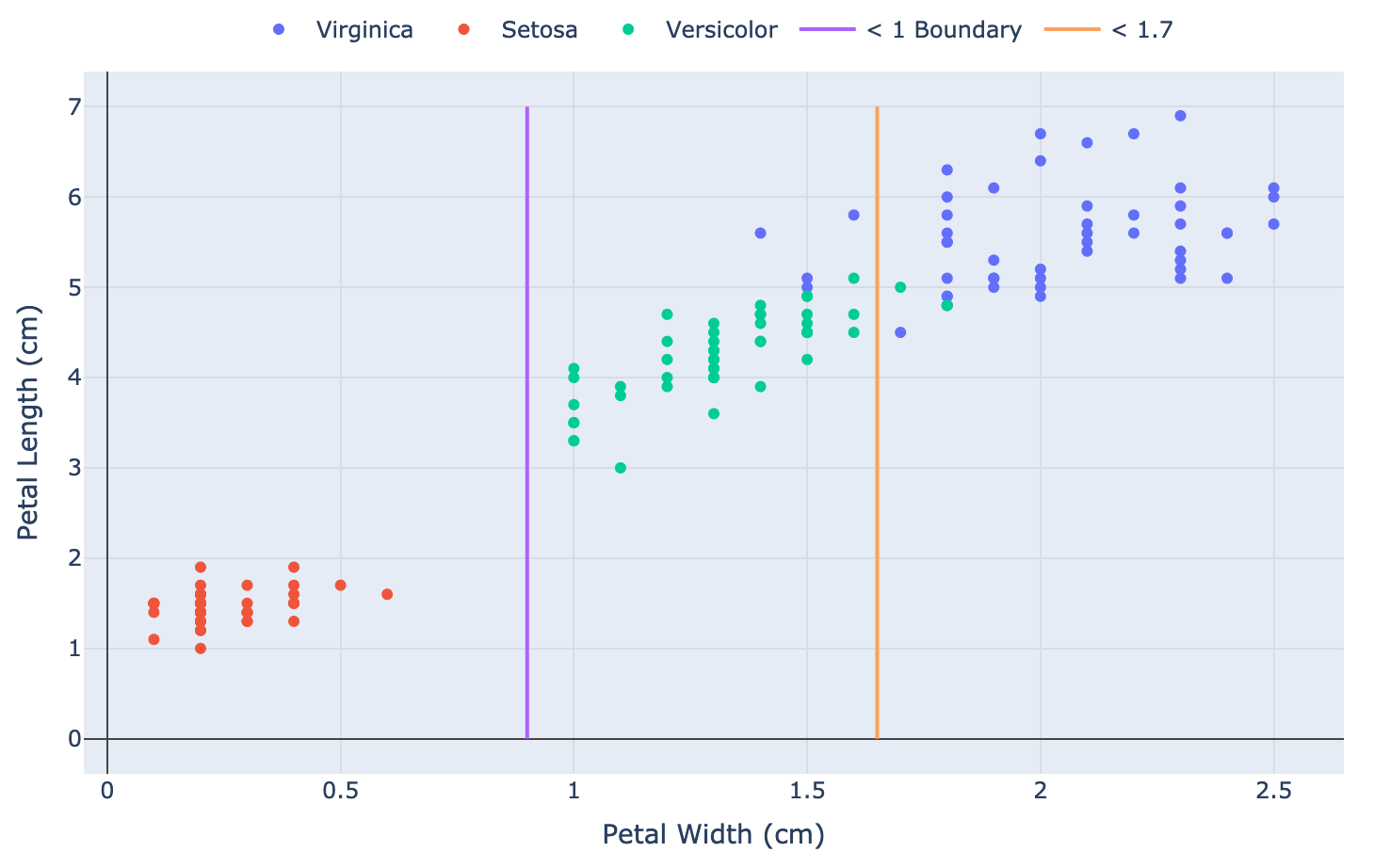
That’s what 1R is about. BTW, there is an even more straightforward rule, called 0R (“zero rule”). This is the most common species in the dataset. That is, you pick the most popular classification, and you predict that for everything.
What I learned from implementing this algorithm
I implemented the algorithm to stretch my Rust muscles and get some more experience with the language and ecosystem. There are arguably more convenient versions of 1R in R and Python, so you don’t need this code.
But here’s what I learnt.
Documentation
This was my first go at publishing Rust crates. As mentioned, I split the code into two crates and implemented an application to dog food them.
The culture of docs.rs means I’ve ended up writing much better user documentation that I would have. It just seems to be expected. Plus, having Rust compile and test the code in comments, means there are no real excuses not to.
Data science
I’m struggling with a lack of a data frame or similar construct for holding test data. I’ve selected ndarray as a basis for data mangling. I did that because it seems to have a good ecosystem, which I’m still learning about.
Performance
I picked Rust, partly because I like it, but also for performance. (Not just for this project, but for a few machine learning projects I’m working on: I have a bunch of computations I want to run fast).
I’ve not tried to optimise the running of the code in any way at all. I know I’m doing some suboptimal things in places, but those are things I can fix in time.
I did just assume Rust be faster for these scenarios compared to my go-to language of Scala. However, I eventually did test out that assumption on a simple project that’s representative of the kinds of things I want to do. I used GraalVM native compilation as a comparison. As expected, Rust is a lot faster. For me. On these projects. There are still lots of applications where this doesn’t matter. But for what I’m working on right now, this is reassuring.
Repeatability
For the work I’m doing I want to be able to replicate anything I do at a later date. Given a Git commit hash, a set of parameters, I want the same data to produce the same results. I thought I had this sorted with storing a random number seed, but I was getting variable results.
I traced this down to Rust’s default hasher. I was computing a frequency count by using a hash map, and the hash map is randomly seeded (for good security reasons).
The incantation to use a deterministic hasher was:
// with dependency: rustc-hash = "1.1.0"
use std::collections::HashMap;
use std::hash::BuildHasherDefault;
use rustc_hash::FxHasher;
let deterministic_hasmap =
HashMap::with_hasher(BuildHasherDefault::<FxHasher>::default());
I found it interesting that the type of this value is not a HashMap<K, V> but instead includes the hasher in the type signature:
HashMap<K, V, BuildHasherDefault<FxHasher>>
…for some key and value, where FxHasher is the deterministic hasher I’m using.
Summary
It’s been a lot of fun implementing this in Rust. I think taking on an algorithm and pushing through to implement it all is a good way to grow your knowledge of a language.
And as a consequence, there are now two crates and an application relating to 1R, if you want to try them out.
Resources
Holte, R.C. (1993) Very Simple Classification Rules Perform Well on Most Commonly Used Datasets. Machine Learning 11: 63. https://doi.org/10.1023/A:1022631118932. This is the original paper, containing many experiments evaluating the performance of 1R on datasets of the time.
Molnar, C. (2019) Interpretable Machine Learning. In particular: Learn Rules from a Single Feature (OneR). I first read of 1R in this book.
Nevill-Manning, C. G., Holmes, G. & Witten, I. H.(1995) The development of Holte’s 1R Classifier. (Working paper 95/19). Hamilton, New Zealand: University of Waikato, Department of Computer Science. https://hdl.handle.net/10289/1096 This is useful to get an understanding of how quanitsation works out in 1R. I’ve not implemented any of the improvements.
Shahin Rostami’s in-progress book on Data Analysis with Rust Notebooks was a great use in noodling with ndarray.
https://docs.rs/ndarray/ is the documentation for the ndarray crate in Rust.
Rust hashmap documentation for a description of the default configuration.
https://en.wikipedia.org/wiki/Iris_flower_data_set if you’re interested in that Iris dataset.
Rui Pereira, Marco Couto, Francisco Ribeiro, Rui Rua, Jácome Cunha, João Paulo Fernandes, and João Saraiva. 2017. Energy efficiency across programming languages: how do energy, time, and memory relate? In Proceedings of the 10th ACM SIGPLAN International Conference on Software Language Engineering (SLE 2017). Association for Computing Machinery, New York, NY, USA, 256–267. DOI:https://doi.org/10.1145/3136014.3136031 When I mentioned performance, I didn’t mention energy. Rust does well in this measure.