
The figure often quoted for the size of chemical space is 10⁶⁰. That’s the estimate for how many molecules you can make by joining atoms together in different ways (“synthetically accessible organic molecules”).
Wolfram Alpha tells me the number is called 1 novemdecillion:
1,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000
It’s one of those crazy big numbers: even if you could look at 100 trillion molecules a second, to complete the job you’d need more than 20 order of magnitude more time than the age of the universe.
But where does that estimate come from? The source cited is Bohacek, McMartin & Guida The art and practice of structure-based drug design: A molecular modeling perspective in Medicinal Research Reviews from 1996.
The size of the space is described on page 42 as “very large”:
With the development of combinatorial libraries, it is becoming possible to screen large numbers of compounds. However, as indicated in Fig. 6, the universe of potential molecules is very large, and it is by no means certain that libraries of synthetic compounds, whether combinatorial or not, will adequately sample this universe.
The magic number itself turns up in a figure caption in page 43:
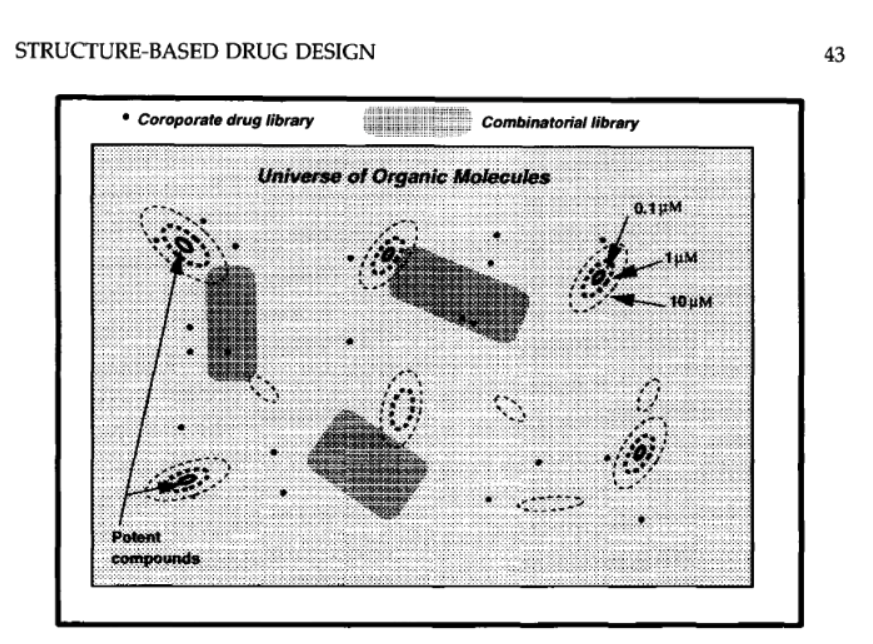
The caption reads:
Schematic illustration of a search for lead compounds by screening. Molecules are assumed to be arranged so that similar molecules are close to each other. A subset of molecules containing up to 30 C, N, O, and S atoms may have more than 10^60 members*. Contours show regions where the molecules are potent inhibitors for a specific (in this case hypothetical) binding site.
OK, and there’s an asterisk footnote on that. We follow it:
Although the number of possible molecules is difficult to estimate accurately, simple considerations show that it must be very large! Consider growing a linear molecule an atom at a time and choosing a carbon, nitrogen, oxygen, or sulfur atom at each position. Some of these atoms can be doubly or triply bonded, but not all combinations of atoms are chemically stable, and some multiple bonds will only be possible in nonlinear structures, i.e., a C—O group. Assuming a very approximate average choice multiplicity of 6, then 6^30 or 2 x 10^23 molecules could be grown containing 30 atoms. Now consider the ways of introducing branching or cyclization into the resulting structure. Closure of rings with three or more atoms involves selecting two atoms to form a bond and could be achieved in 30*28/2 ways. Making a branched molecule could be achieved by choosing a point to cut the chain and a point in the first part of the chain to attach to the cut end of the second part of the chain (i.e., 30^2 ways). Not all atoms can be joined in this way. However, this will be offset by the fact that when stereochemical considerations are introduced, the number of possibilities will be expanded. Based upon these considerations, approximately 10^40 molecules with up to four rings and 10 branch points could be produced from each linear chain, resulting in a very approximate estimate of 10^63 molecules in total. Although this is a rough estimate, it seems likely that when all the different possible combinations of ring closure and branching are taken into account, the true number will be well in excess of 10^60 and will rise steeply with increasing molecular weight.
So that’s how that number was reached, as described in a footnote to a caption.
I can sense why the authors needed to estimate this. In discussing the design of new lead compounds, they reference GrowMol, their program to “grow molecules” (in silico), and illustrate atom-by-atom search:
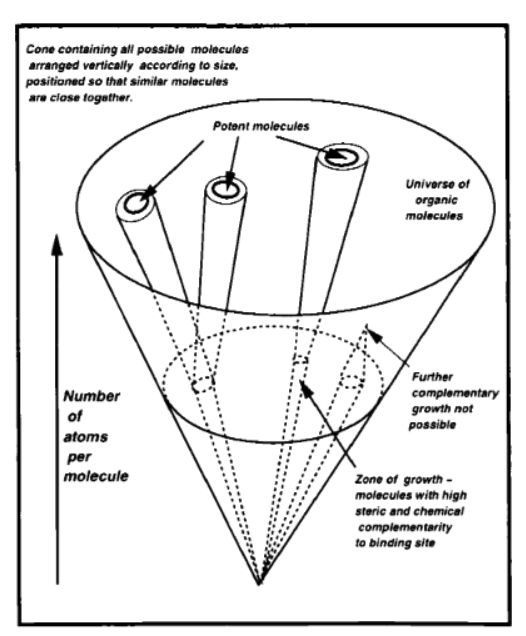
They optimistically note:
Figure 7 shows how, with suitable rules for growing the molecule an atom (or functional group) at a time, and a probabilistic rejection of new atoms based on complementarity, it may in the future be possible to search the entire universe of small organic molecules for potential drugs. (p. 44)