
Reading: Question-based computational language approach outperforms rating scales in quantifying emotional states, Sikström et al. (2024), Communications Psychology.
The gold standard of psychological assessment is a mental state interview with a psychologist. But second to that are rating scales: questionnaires where you strongly, or otherwise, agree or disagree with statements. Examples include PHQ-9, GAD-7, DASS. There are many different “inventories” out there, enough for a call to establish agreed common metrics.
Despite some having slightly awkward licensing terms and most having various bias limitations, inventories are generally quick, not too painful, and give you a score you can track it over time. But can we do better, now we have some pretty remarkable natural language tools (I’m looking at you, LLMs)?
This study demonstrates that, on average, employing computational methods based on a single open-ended question with a five-word response format yielded higher accuracy in categorizing participant-generated narratives describing emotional states compared to using four standardized rating scales.
In other words:
- ask someone a single open-ended question (which “may convey a more person-centered and holistic representation of one’s mental state”); and
- compute a score from that.
Example question:
Please write a text about a period in life (days to months) when you experienced anxiety. Please answer the question by writing at least a paragraph (approximately five sentences). Write about those aspects that are the most important and meaningful to you. Note. Please do not use the word ‘anxiety’
Here’s an example response:
After I had a medical condition diagnosed. Did not want to leave the house, felt scared and a feeling that something would go wrong constantly.The thoughts of it consumed me, always going to the worst case scenario. I hated telling people and began to withdraw from the world, comfortable only being alone in my own house and not venturing far at all.
From that, the subject was asked to write five descriptive words. For the example above, the words were: “Fear worried engulfed inadeuate (sic) paranoid”. And complete the self-assessment rating scales (GAD-7 etc).
The result: five descriptive words gave the best categorization of mental state. The whole study looks like this:
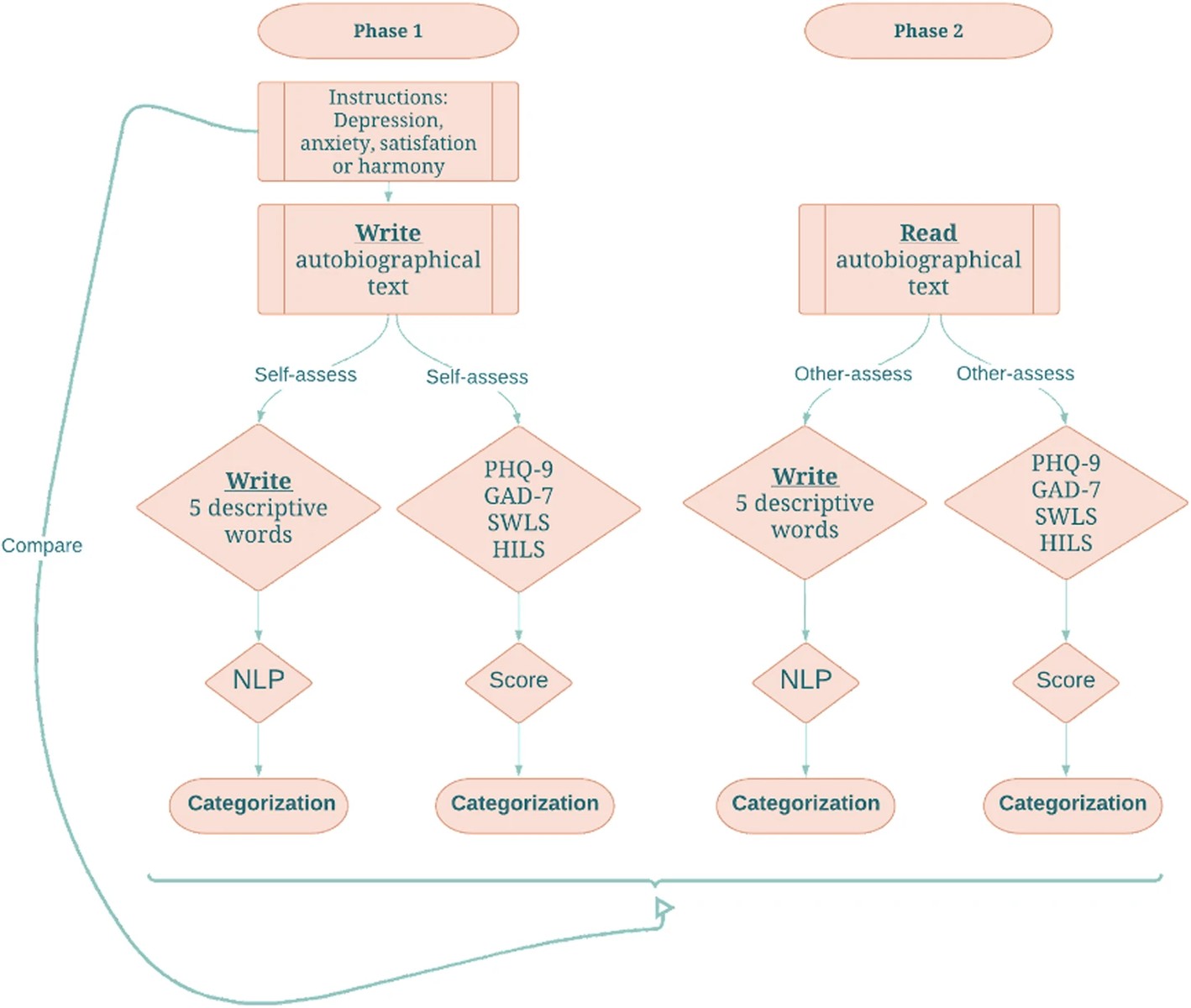
The computational side was using an embedding from BERT for the 5 words, and training a model on this semantic vector. It took me a while to understand what the target of the model was (that is, what it is trained to predict): it’s the emotion the subject was asked to write about.
The study was able to recover that emotion best from the five words, and in particular, a lot better than from the standardized rating scales: 64% vs 44%.
Even considering the individual rating scales, the five words approach did better:
Basing the categorization on individual items of the four rating scales (26 items in total, i.e., 9 items for PHQ-9, 7 for GAD-7, and 5 for SWLS and 5 HILS) yielded lower categorization accuracy (30%)
I can imagine this, when further advanced, being added into therapy platforms and as less intrusive way to measure treatment progress.