
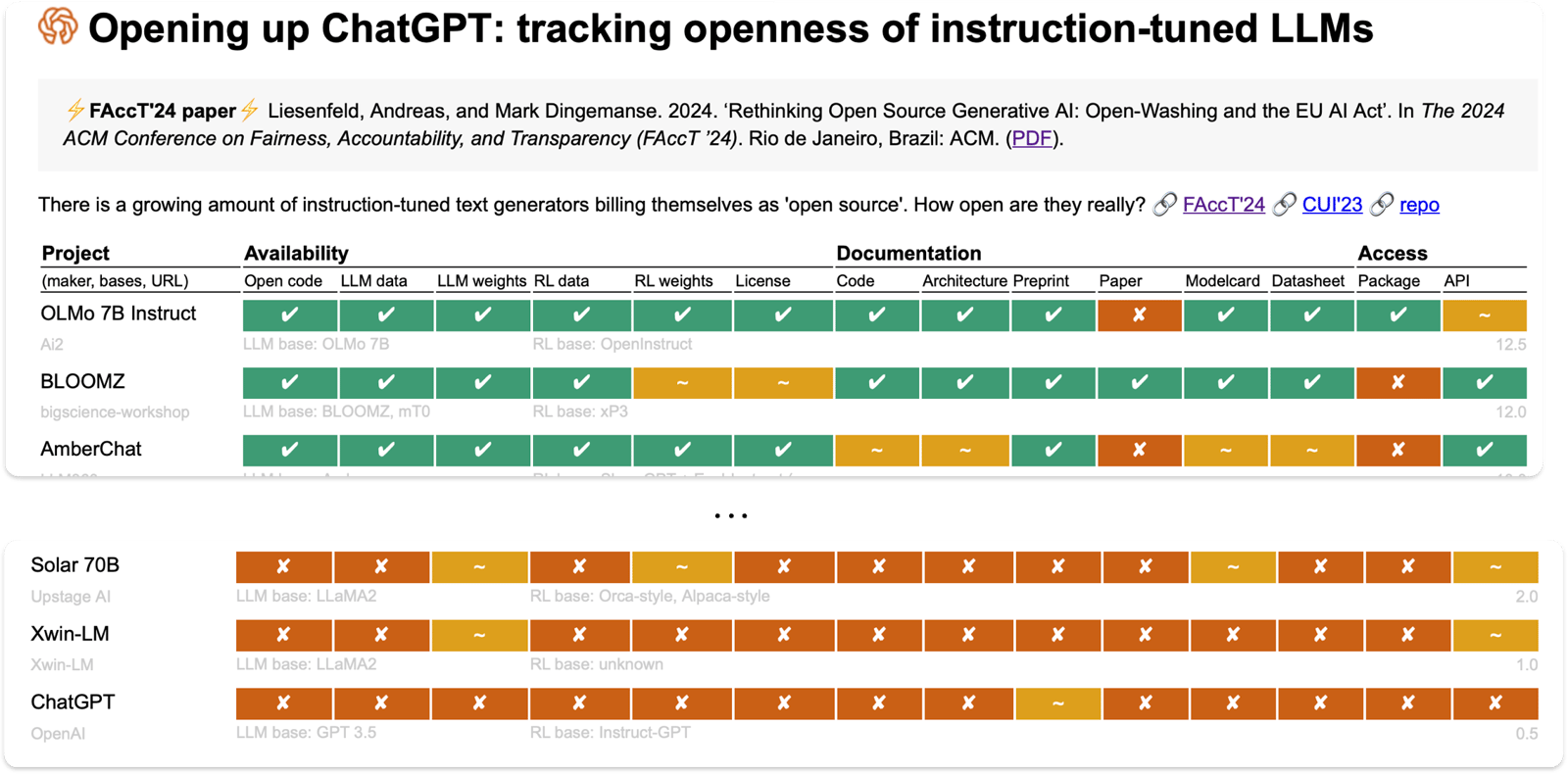
The research on how open LLMs are includes a column for “LLM data”. The top of that list is OLMo from Ai2 (the Paul Allen Institute for AI).
Jeremy raises excellent ethical points on the use of LLMs, and the one that resonates most with me is the use of copyrighted material. So here we are: a model that attempts to addresses one data problem.
The data comes from Common Crawl, Semantic Schollar, Wikipedia, Gutenberg, and elsewhere. You can get the data and inspect it—at least in principle, as there is a lot of it. You can also ask for your data to be removed, at least from Common Crawl, and possibly the other sources.
I downloaded OLMo 7B July 2024 Instruct (the data is listed on that page, under the side heading “Datasets used to train”). Using my usual Python environment I gave it a go:
# A tool to run a model
brew install llama.cpp
# The model:
git clone https://huggingface.co/allenai/OLMo-7B-0724-Instruct-hf
# Convert the model to run with llama.cpp:
git clone git@github.com:ggerganov/llama.cpp.git
cd llama.cpp
pip install -r requirements.txt
python convert_hf_to_gguf.py ../OLMo-7B-0724-Instruct-hf \
--outfile olmo-instruct-7b-q8 --outtype q8_0
# Run the model
llama-cli -m olmo-instruct-7b-q8 \
-p "You are a helpful assistant" -cnv
I won’t bother showing any output here—you know what LLM chat looks like. I will describe how it has changed the way I use LLMs.
OLMo is much less capable than my usual diet of Perplexity, Claude, NotebookML and OpenAI. As a result, it has made me more critical of the output. I have rediscovered using DuckDuckGo to get answers. This is all positive, btw.
What OLMo is good for is:
- Knocking out a quick bash script or Python code
- Opening up a discussion, and giving different avenues to explore. I was trying to avoid using the word “brainstorming” there.
- Related to that, helping recall something from a vague description.
As an example of that last item, I was trying to remember the phrase “bloom filter” and my search engine attempts were getting me nowhere. A one sentence description of what I was thinking to the LLM got me the answer straight away.
I think this is all telling me that I have fallen into a default to using LLMs over search engines. I’m now readjusting to defaulting to search for “answers”, using LLMs for quick highly specific scripts, and vague explorations.
I’ll keep my local LLM running, and will use it. But not for everything.
* * *
I’m lucky enough to have a laptop that can run these things fast enough. Apparently I have 14 TFLOPS of computing power balanced on my knees.
What?
That sounds like a big number, but it’s middling-to-low in some ratings.
Still, looking at the timeline of high-performance computers, this means my laptop would have been the #1 supercomputer of 2001—although I don’t have the 6TB of memory available to the Lawrence Livermore Lab ASCI White, nor would my knees support 106 tons.