
Reading: Faithfulness Hallucination Detection in Healthcare AI, Vishwanath et al (2024), paper accepted to KDD-AIDSH 2024.
Fifteen clinicians were taught to use an annotation tool to find and classify hallucinations from 50 medical notes summarised by GPT-4o or Llama-3:
Table 1 reveals that both GPT-4o and Llama-3 exhibit hallucinations on almost all the examples.
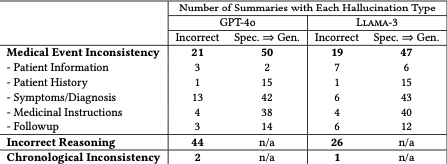
Well that looks pretty bad.
But a couple of notes.
First, this is a paper jointly authored with a company that makes a tool for hallucination detection. Nothing wrong with that.
Second, the prompt used doesn’t look like it had much optimisation on it to reduce hallucinations:
Summarize the provided clinical note with at most {n} words. Ensure to capture the following essential information, when they exist: the specific cancer type, its morphology, cancer stage, progression, TNM staging, prescribed medications, diagnostic tests conducted, surgical interventions performed, and the patient’s response to treatment.
{clinical note}
It seems like a low bar to set. Sadly, the proposed future work doesn’t include improving the prompt. It could be that this is just a problem that’s too hard, and prompt Whac-A-Mole won’t solve it. I don’t think this work tells us that.
However, I totally understand why they used a fixed prompt in their pilot:
The average annotation time per note was 91.5 minutes.
Ouch! But so it’s an important problem to make progress on.